咨询电话:17688764798 咨询电话:17688764798
咨询电话:17688764798 咨询电话:17688764798 

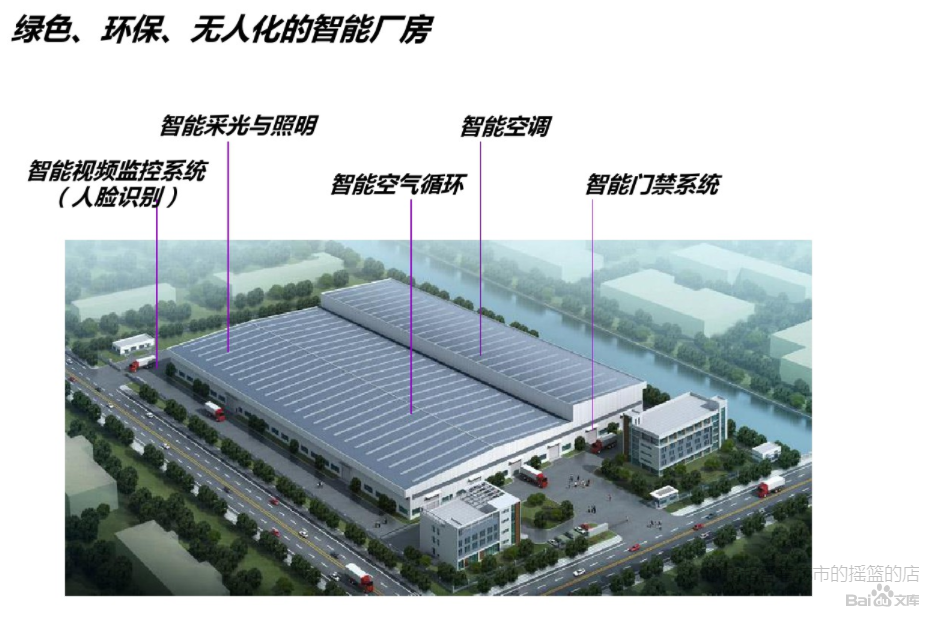
鸿鹄(深圳)创新技术有限公司,重新定义中国智造:AIM智能制造系统=智能算法+智能设备+现有生产线。
精于省 竭尽全力为客户
产品连续多年被列入“ 优质产品
优质产品多项国家专利技术
 企业实力
企业实力多项荣誉加身
 产品资历
产品资历信息系统安全CNAS认证
 全程服务
全程服务社会人员技术培训,提高系统标准化和售后服务团队
技术百科
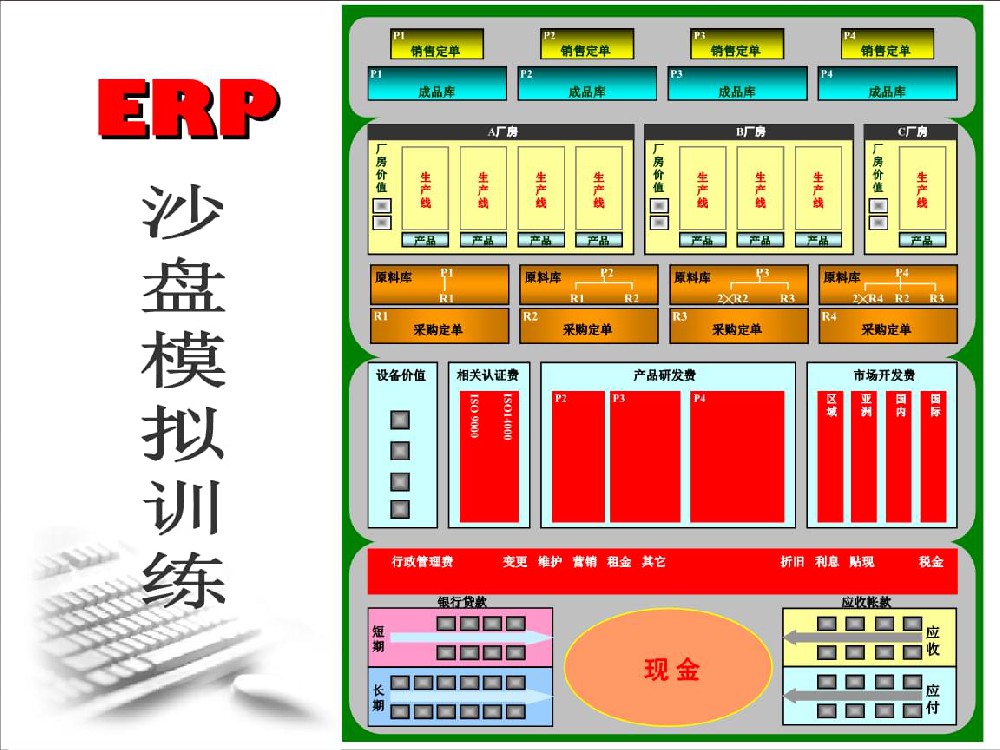
2024-03-27什么是ERP系统?
【欢迎关注,分享更多职场干货】ERP是什么?ERP是英文 Enterprise Resource Planning的首字母简写,是指企业···产品知识